
A huge step forward in the field of brain2text. A bit uncanny but it works.

What’s the topic?
Representing the complex mental contents of humans as text, purely by decoding brain activity (brain2text).
What’s the big deal?
According to Tomoyasu Horikawa (NTT Communication Science Laboratories, computational neuroscientist):
For more than a decade, researchers have been able to accurately predict, based on brain activity, what a person is seeing or hearing, if it’s a static image or a simple sound sample.
However, decoding complex content—such as short videos or abstract shapes—had not been successful until now.
Now, for the first time in history, the content of short videos has been represented as text with high accuracy, purely by decoding the brain activity measured while watching the videos.
How does it work?
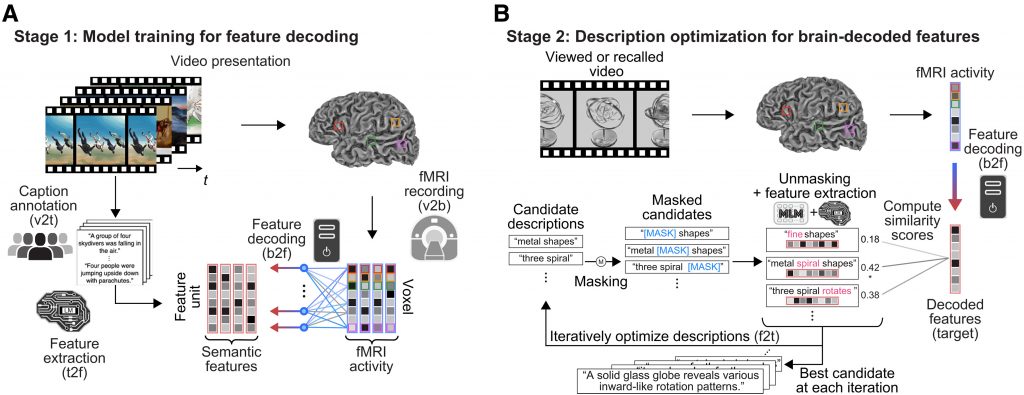
Based on Tomoyasu Horikawa’s research report, their team’s procedure generates descriptive text that reflects brain representations using semantic features computed by a deep language model.
They built linear decoding models to translate brain activity induced by videos into the semantic features of the corresponding captions, then optimized the candidate descriptions by adjusting their features—through word replacement and interpolation—to match those decoded from the brain.
This process resulted in well-structured descriptions that accurately capture the viewed content, even without relying on the canonical language network.
The method was also generalizable to verbalizing content recalled from memory, thus functioning as an interpretive interface between mental representations and text, and simultaneously demonstrating the potential for nonverbal, thought-based brain-to-text communication, which could provide an alternative communication channel for individuals with language expression difficulties, such as those with aphasia.
What was the big idea?
Some previous attempts used artificial intelligence (AI) models for the whole process in one. While these models are capable of independently generating sentence structures—thus producing the text output—it is difficult to determine whether the output actually appeared in the brain or is merely the AI model’s interpretation.
Here comes Horikawa, who splits the process into two stages and by the separation prevents the above mentioned problem from occurring.
This is the big idea, in my opinion.
Horikawa’s method is to first use a deep language AI model to analyze the text captions of more than 2,000 videos, turning each into a unique numerical “meaning signature. (Stage 1).
Then a separate AI tool was then trained on the brain scans of six participants, learning to recognize the brain activity patterns that matched each meaning signature while the participants watched the videos (Stage 2).
Clever, I like it.
So, if you are uncertain about what depends on what and how in the system, make separations, introduce phases and the picture will become clearer! Especially if AI is also in play…
References:
Leave a Reply